Research Highlights
In top venues
Complete list
Refer to Google Scholar and DBLP for more updated information.
2026
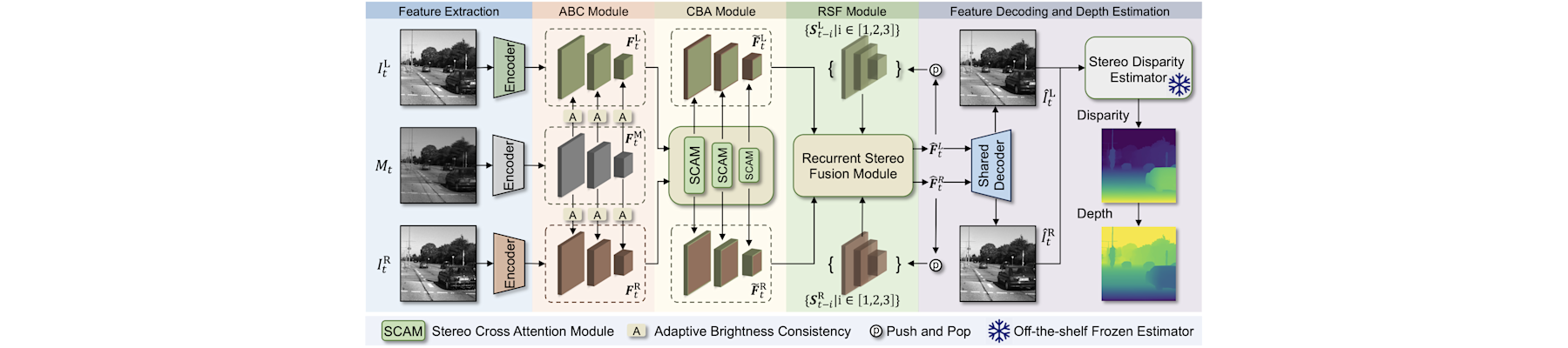
[CVPR26a] 240FPS stereo vision from monocular mixed spikes
Yeliduosi Xiaokaiti, Yakun Chang, Yang Bai, Zhaojun Huang, Peiqi Duan, and Boxin Shi
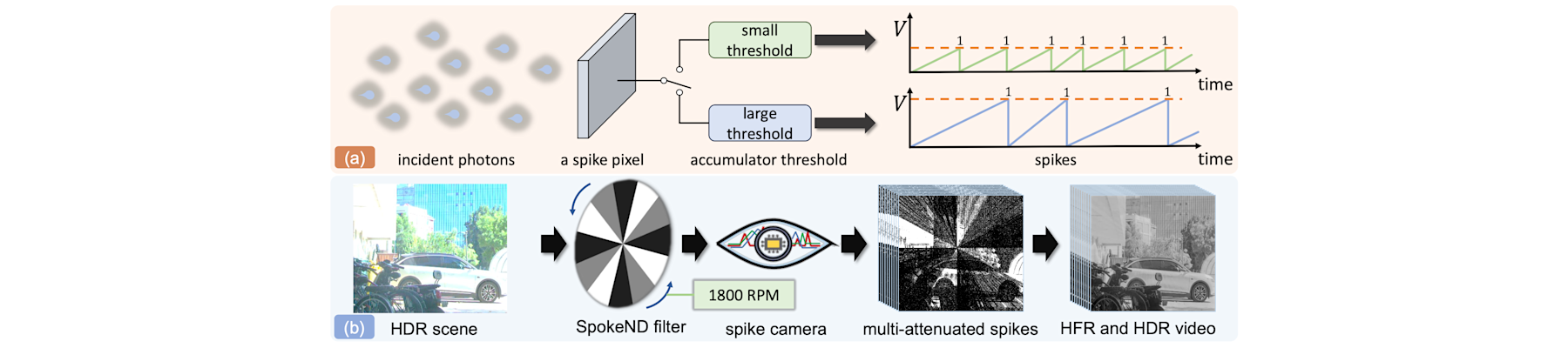
[CVPR26b] HFR and HDR video from multi-attenuated spikes using a rapidly rotating SpokeND filter
Yakun Chang, Zhaojun Huang, Siqi Yang, Yeliduosi Xiaokaiti, Shikui Wei, Yao Zhao, Tiejun Huang, and Boxin Shi
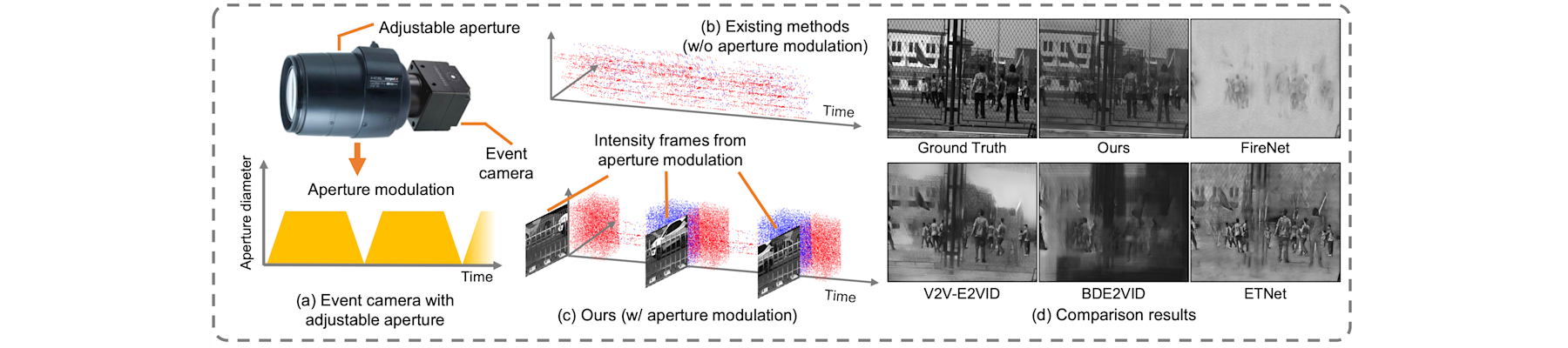
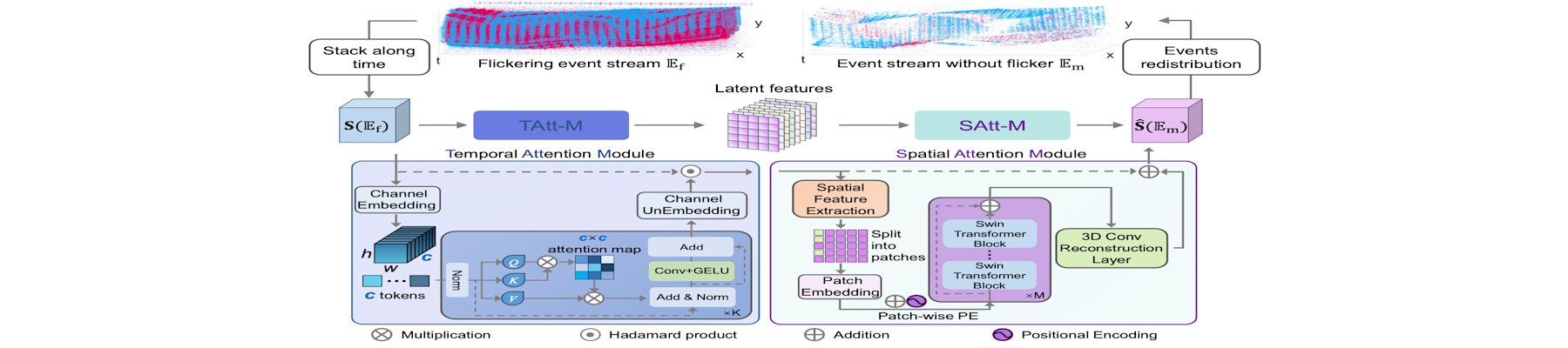
[CVPR26c] AE2VID: Event-based video reconstruction via aperture modulation
Chenxu Bai, Boyu Li, Peiqi Duan, Xinyu Zhou, Hanyue Lou, and Boxin Shi
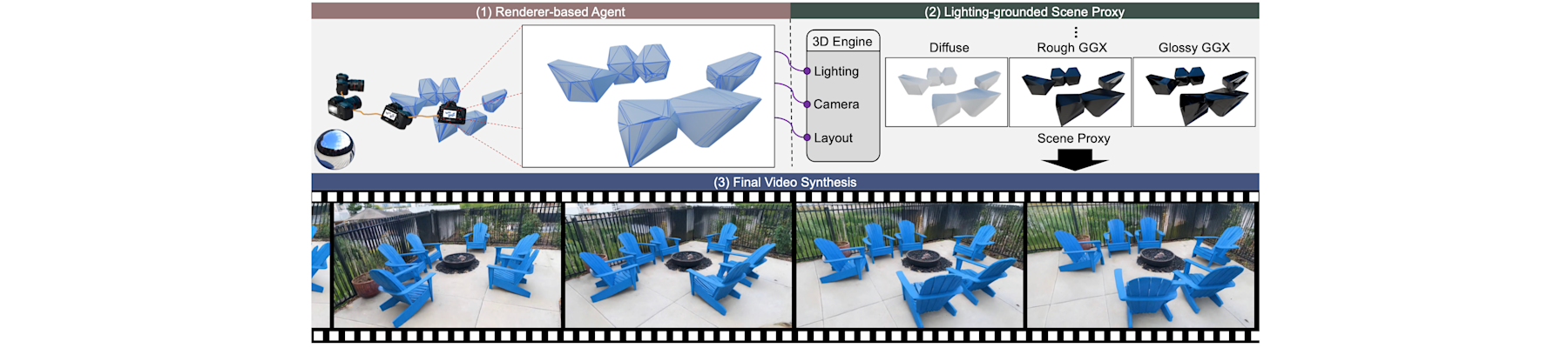
[CVPR26d] Lighting-grounded video generation with renderer-based agent reasoning
Ziqi Cai, Taoyu Yang, Zheng Chang, Si Li, Han Jiang, Shuchen Weng, and Boxin Shi
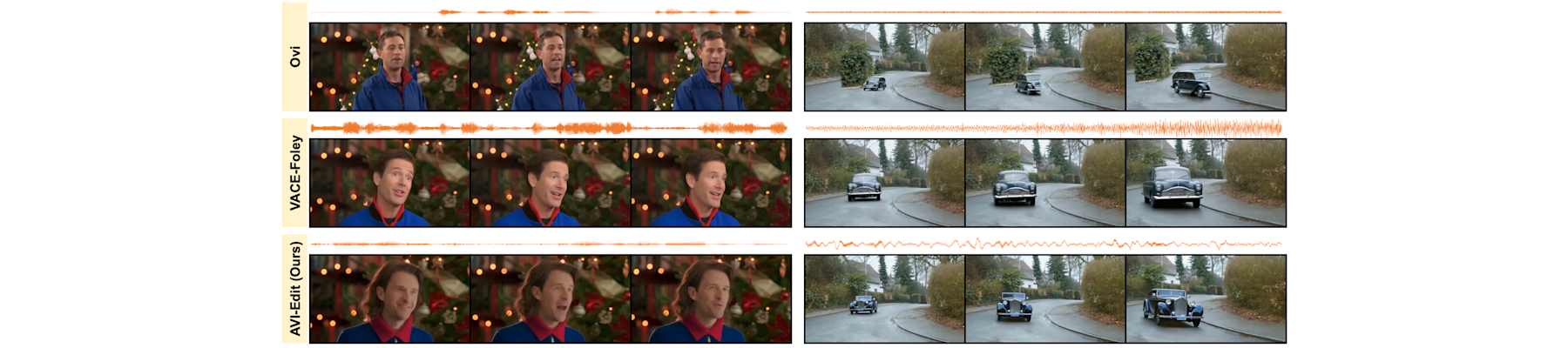
[CVPR26e] Audio-sync video instance editing with granularity-aware mask refiner
Haojie Zheng, Shuchen Weng, Jingqi Liu, Siqi Yang, Boxin Shi, and Xinlong Wang
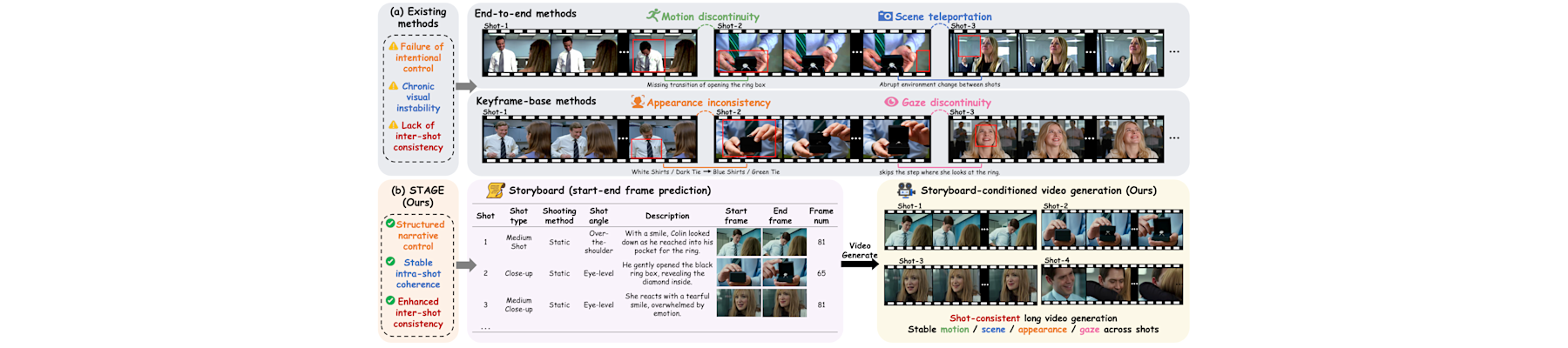
[CVPR26f] STAGE: Storyboard-anchored generation for cinematic multi-shot narrative
Peixuan Zhang, Zijian Jia, Kaiqi Liu, Shuchen Weng, Si Li, and Boxin Shi
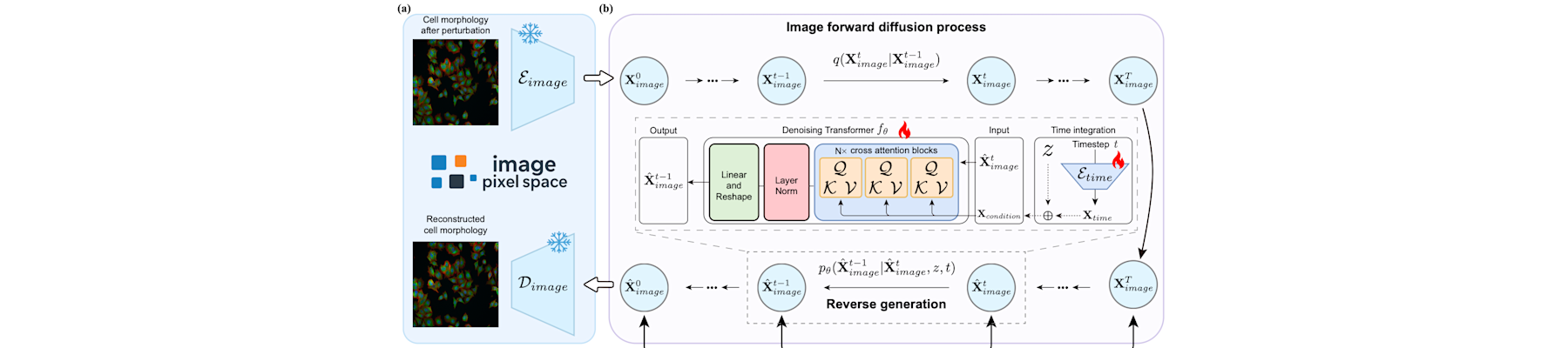
[CVPR26g] TRIDENT: A trimodal cascade generative framework for drug and RNA-conditioned cellular morphology synthesis
Rui Peng, Ziru Liu, Lingyuan Ye, Yuxing Lu, Boxin Shi, and Jinzhuo Wang

[CVPR26h] Texvent: Asynchronous event data simulation via text prompt
Ruofei Wang, Peiqi Duan, Ka Chun Cheung, Simon See, Boxin Shi, and Renjie Wan
2025
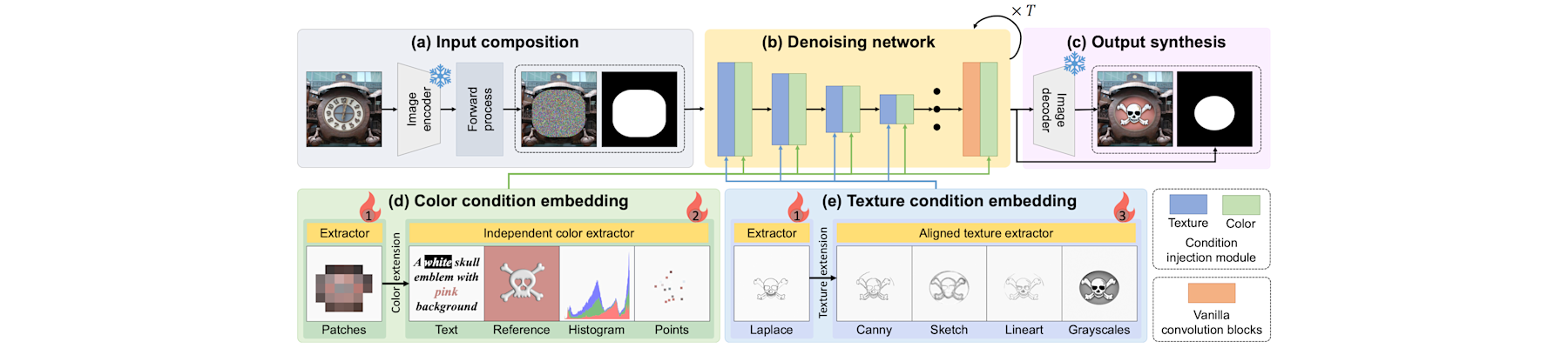
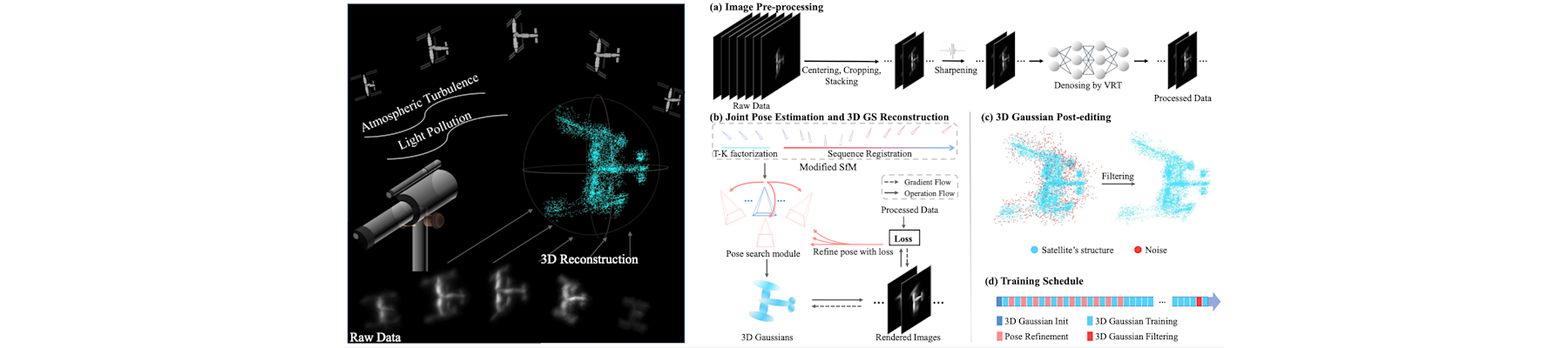
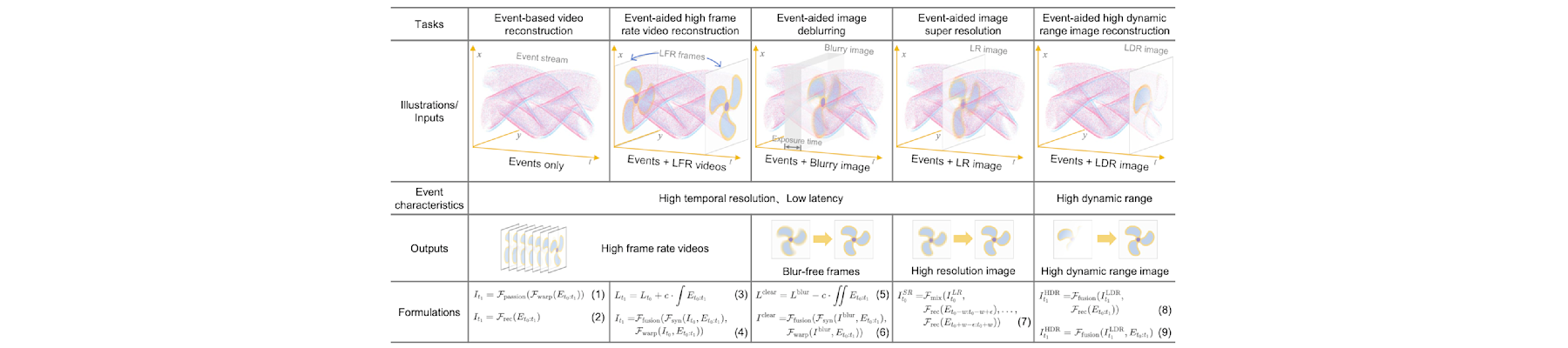
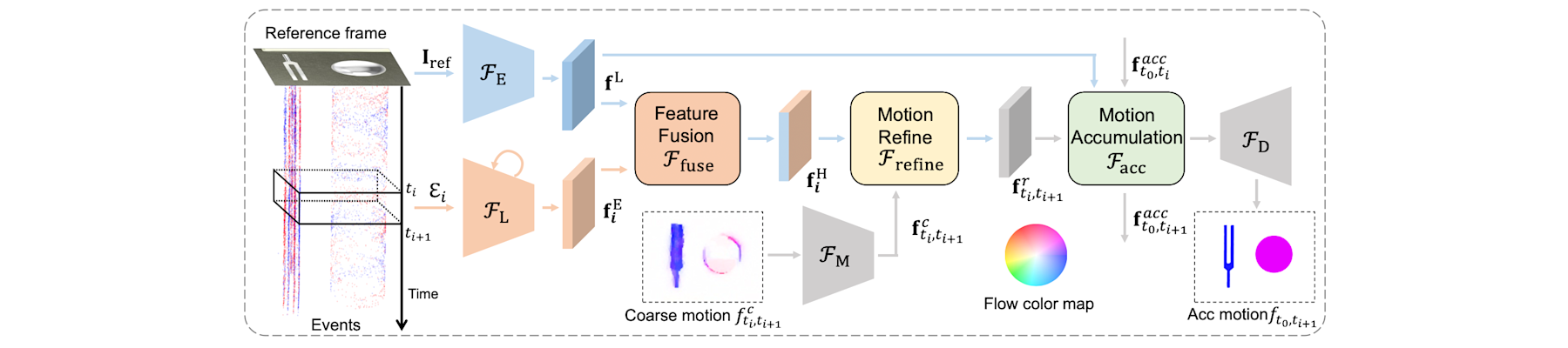
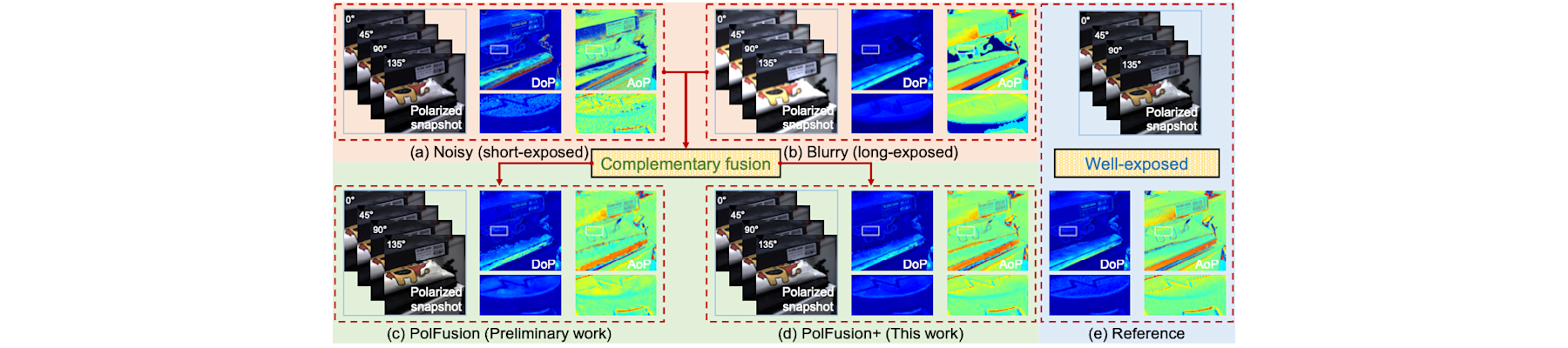
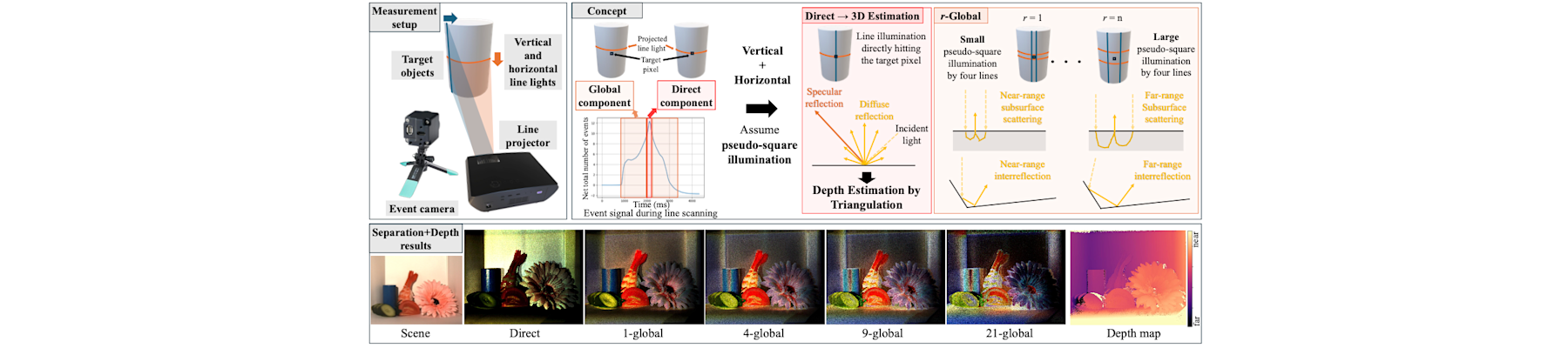
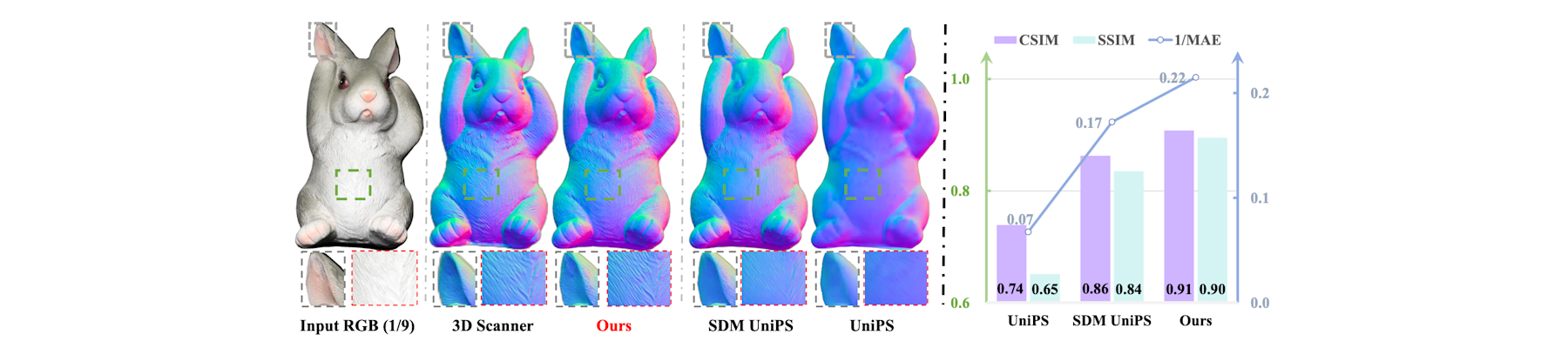
[TPAMI25c] EventAid: Benchmarking event-aided image/video enhancement algorithms with real-captured hybrid dataset
Peiqi Duan, Boyu Li, Yixin Yang, Hanyue Lou, Minggui Teng, Xinyu Zhou, Yi Ma, and Boxin Shi
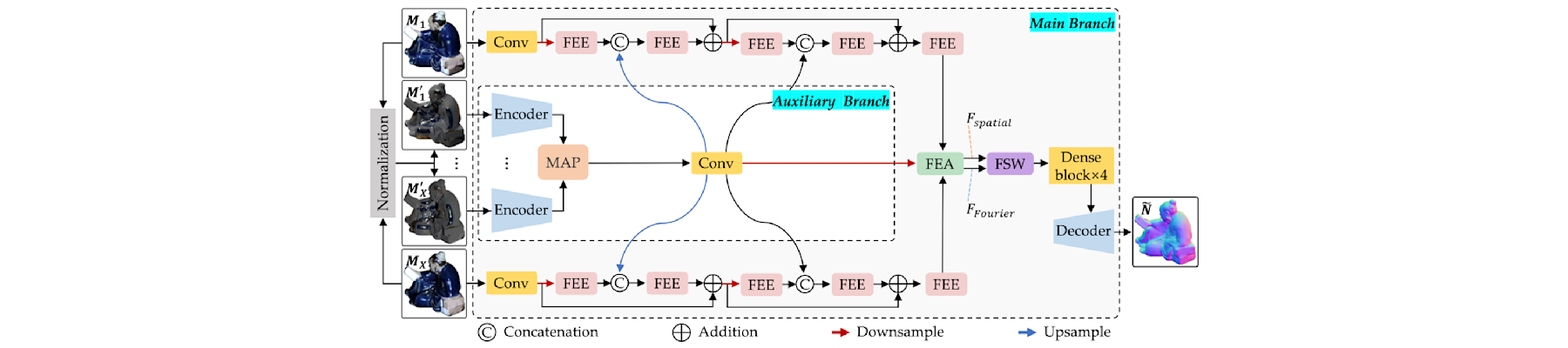
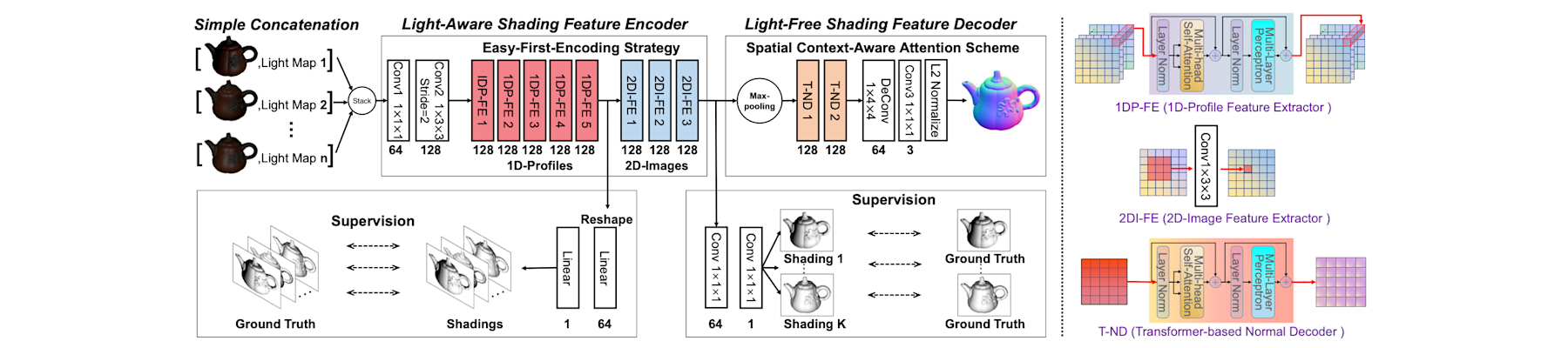
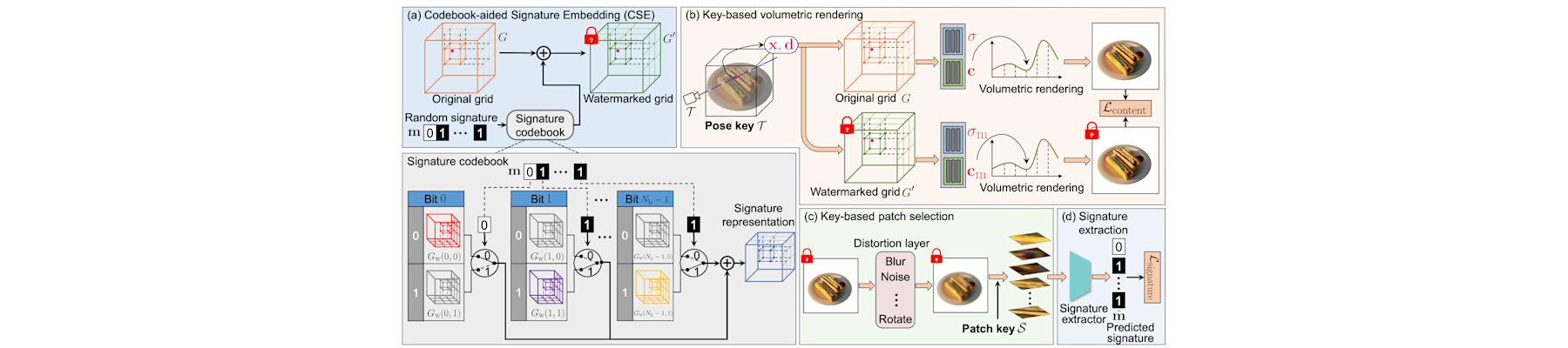


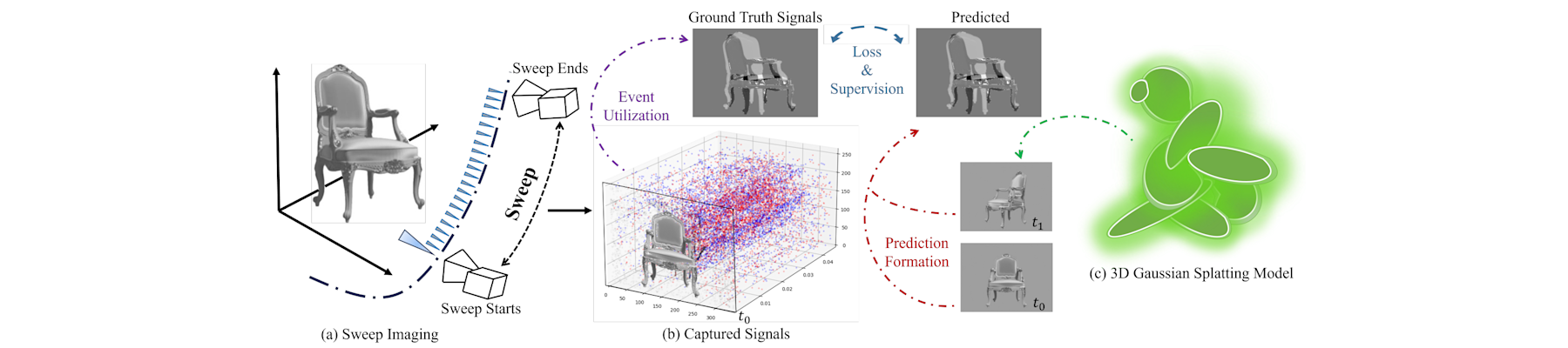
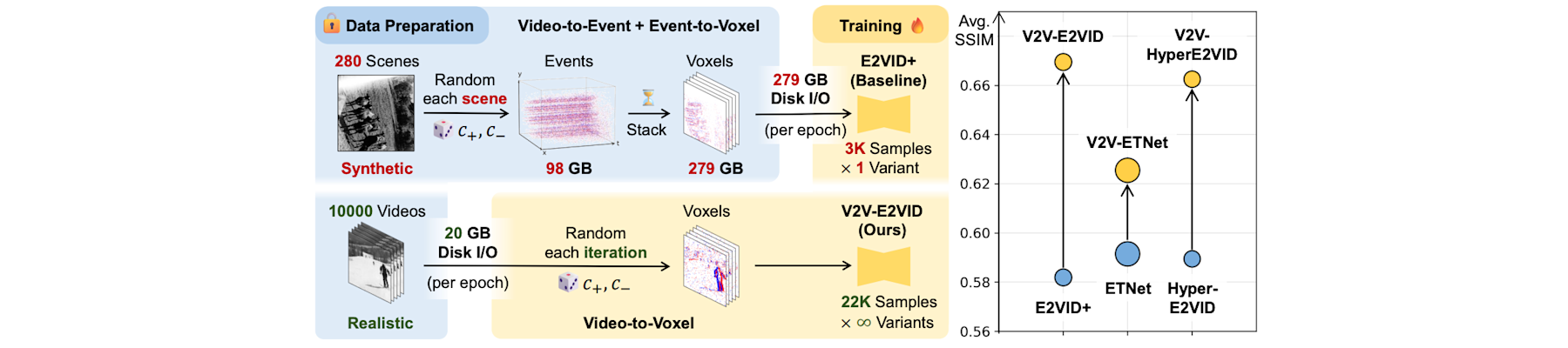
[NeurIPS25a] V2V: Scaling event-based vision through efficient video-to-voxel simulation
Hanyue Lou, Jinxiu Liang, Minggui Teng, Yi Wang, and Boxin Shi
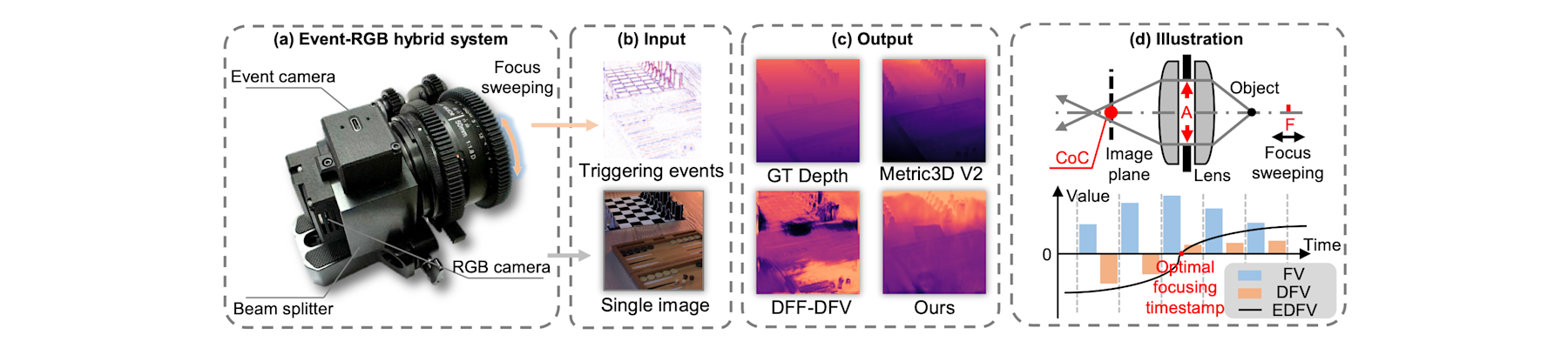
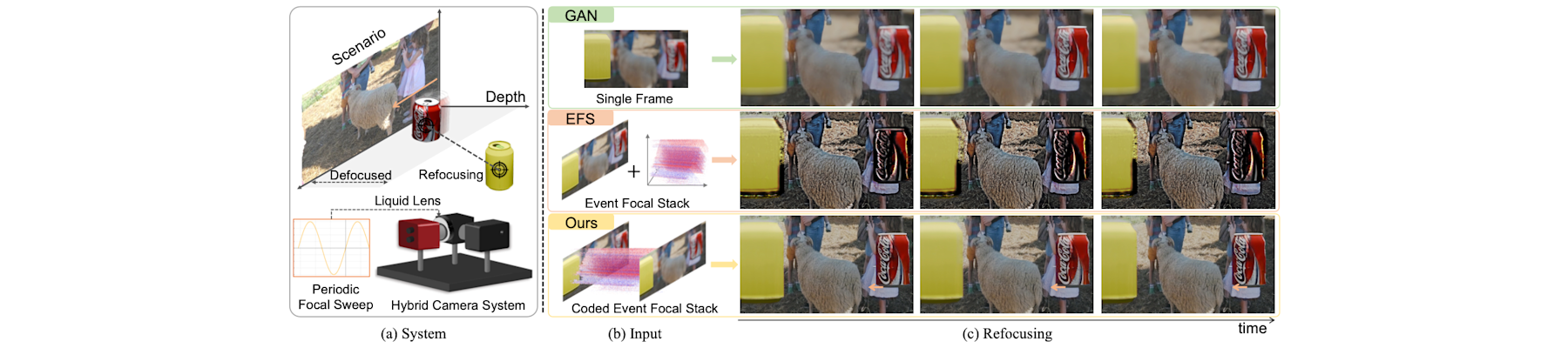
[NeurIPS25b] Dense metric depth estimation via event-based differential focus volume prompting
Boyu Li, Peiqi Duan, Zhaojun Huang, Xinyu Zhou, Yifei Xia, and Boxin Shi
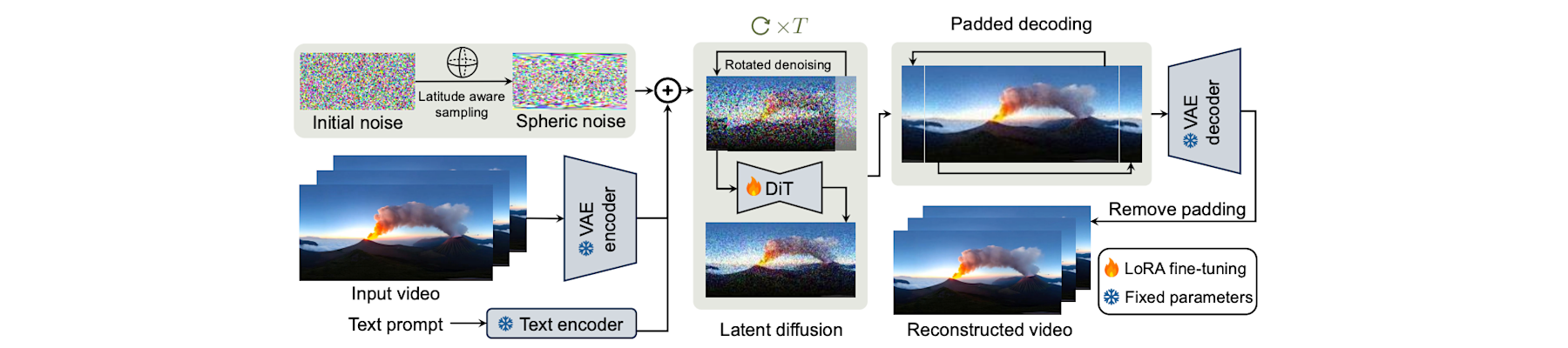
[NeurIPS25c] PanoWan: Lifting diffusion video generation models to 360° with latitude/longitude-aware mechanisms
Yifei Xia, Shuchen Weng, Siqi Yang, Jingqi Liu, Chengxuan Zhu, Minggui Teng, Zijian Jia, Han Jiang, and Boxin Shi
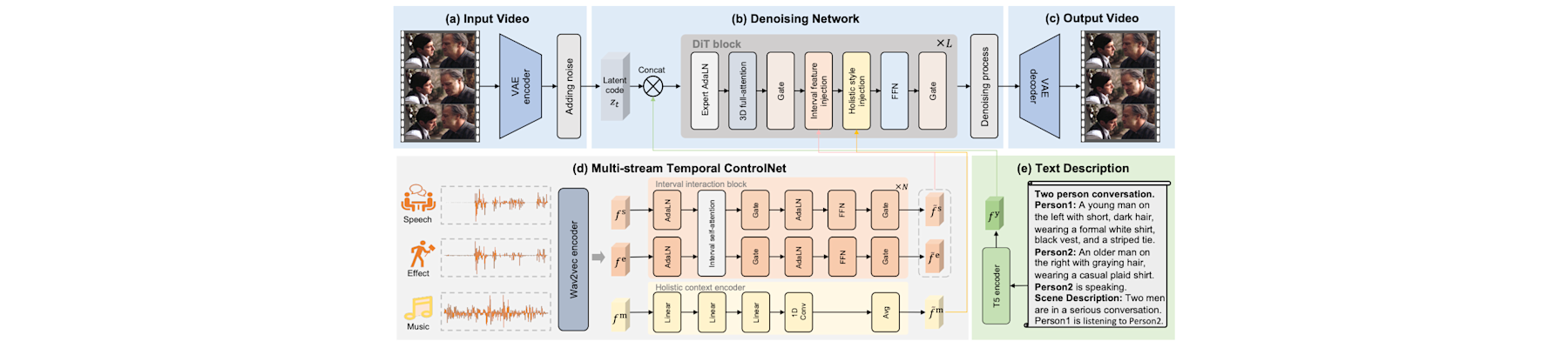
[NeurIPS25d] Audio-sync video generation with multi-stream temporal control
Shuchen Weng, Haojie Zheng, Zheng Chang, Si Li, Boxin Shi, and Xinlong Wang